Websphere Server topologies
Single-server topology:
Provides an application server and a Web site. Initially, a single instance is configured to use an internal database. Convert to a cluster or server farm to improve capacity and availability. WebSphere Portal, WAS, and the database are all installed on the same server.

Optionally configure a Web server, with IBM WAS's HTTP plug-in to...
- Serve static resources
- Provide plug-in point for a corporate SSO agent in the event that WebSphere Portal participates in a global SSO domain
Standalone server topology
The stand-alone scenario is different from the single-server since the database server, LDAP server, and Web server software are installed on different physical servers than the IBM WebSphere Portal. This configuration enables you to distribute the software in the network and therefore distribute the processing load.For a stand-alone configuration, we can use an existing, supported database in the network and an existing, supported LDAP directory. Configure IBM WebSphere Portal to authenticate with the LDAP server. The following illustration displays a common topology for a stand-alone server. The HTTP server, (also referred to as Web server) is installed on a server in a protected network. The LDAP server and database server are also installed on different servers. WebSphere Portal and WAS are installed on the same server.
Choose this topology if you do not require a robust clustered environment. We can also use this option to examine and test functions and features to decide how to accomplish the business goals. We can add this stand-alone production server to a federated IBM WAS Network Deployment cell. It creates a federated, unclustered production server.

Clustered servers topology
IBM WebSphere Portal uses a dmgr server type for clustering portal servers. All portal instances share the same configuration, including...- database
- applications
- portlets
- site design
The HTTP Server plug-in balances user traffic across all members of the cluster. Session affinity ensures that a user remains bound to a specific cluster instance for the duration of their session. When cluster member is down, workload management will route traffic around it.
IBM WebSphere Virtual Enterprise provides dynamic clusters to dynamically create and remove cluster members based on the workload. The On Demand Router has all of the features of the HTTP Server plug-in with the additional ability to define routing and service policies. It is possible to deploy multiple portal clusters in a single cell.
Vertical cluster topology
A vertical cluster has more than one cluster instance within a node. A node typically represents a single physical server in a managed cell, but it is possible to have more than one node per physical server. It is very simple to add additional vertical clusters to a node, using the dmgr console, as each additional vertical cluster instance replicates the configuration of the first instance; no additional installation or configuration is necessary.How many vertical instances that can be created in a single node depends on the availability of physical resources in the local system (CPU and memory). Too many vertical cluster instances could exhaust the physical resources of the server, at which point it is appropriate to build horizontal cluster instance to increase capacity if necessary.
The following diagram illustrates a vertical cluster. A single node has multiple instances of IBM WebSphere Portal installed. The node is managed by the dmgr. Each instance on the node authenticates with the same LDAP server and store data in the same database server. Although not depicted in the illustration, the database and LDAP servers could also be clustered if needed for failover, increased performance, and high availability.

Combination of horizontal and vertical clusters
Most large-scale portal sites incorporate a combination of horizontal and vertical clustering to take full advantage of the resources of a single machine before scaling outward to additional machines.
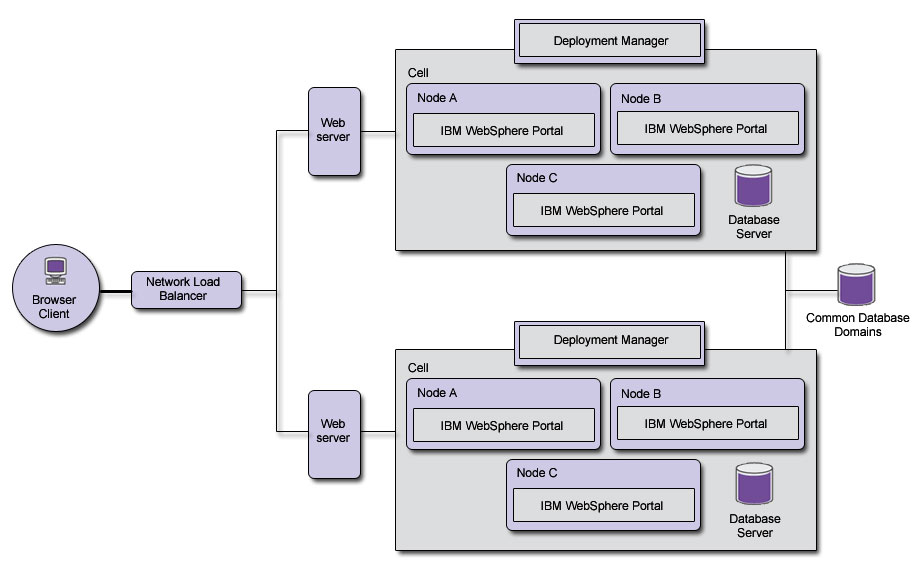
Multiple clusters
With multiple clusters, where each cluster is in a different cell...- One cluster can be taken out of production use, upgraded and tested while leaving other clusters in production, achieving 100% availability with no maintenance windows.
- We can deploy clusters closer to the people they serve, improving the responsiveness of the content.
For the most part, each cluster should be seen as a totally isolated system, administered independently, with its own configuration, isolated from the other clusters. The only exception is with the sharing of the following portal database domains...
- Community
- Customization
These domains store portal configuration data owned by the users themselves.
Each cluster can be deployed within the same data center, to help with improving maintainability and improve failure isolation, or across multiple data centers, to protect against natural disaster and data center failure, or to simply provide a broader geographical coverage of the portal site.
The farther apart the clusters are, the higher the impact network latency may have between clusters and thus the less likely you will be to want to share the same physical database between clusters for the shared domains and will want to resort to database replication techniques to keep the databases synchronized.
Typically, in a multiple portal cluster topology, HTTP Servers are dedicated per cluster, since the HTTP Server plug-in's configuration is cell-specific. To route traffic between data centers (banks of HTTP Servers), a separate network load-balancing appliance is used, with rules in place to route users to specific datacenters, either based on locality or on random site selection, such as through DNS resolution. Domain, or locality, based data center selection is preferred because is predictably keeps the same user routed to the same datacenter, which helps preserve session affinity and optimum efficiency.
DNS resolution based routing selection can cause random behavior in terms of suddenly routing users to another datacenter during a live session. If this happens, the user's experience with the portal site may be disrupted as the user is authenticated and attempts to resume at the last point in the new site. Session replication and/or proper use of portlet render parameters can help diminish this effect.
| active/active | All portal clusters receive user traffic simultaneously from network load balancers and HTTP Servers. If maintenance on one cluster is required, all production traffic is switched to the other cluster. |
| active/passive | Production traffic is routed to a subset of the available portal clusters (e.g. 1 of 2, or 2 of 3). There is always one cluster not receiving any traffic. Maintenance is typically applied first to the offline cluster, and then it is brought into production traffic while each of the remaining clusters are taken out and maintained in a similar fashion. |
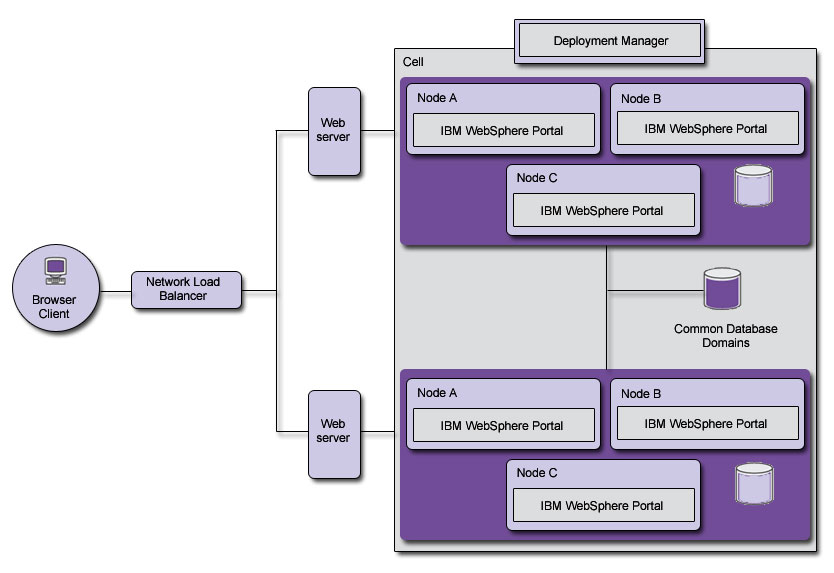
As an alternative to deploying multiple portal clusters where each cluster is in a different cell, it is also possible to deploy multiple portal clusters in the same cell. Different cells give you total isolation between clusters, and the freedom to maintain all aspects of each cluster without affecting the other. Different cells, however, require different dmgrs and thus different Administration Consoles for managing each cluster. Multiple clusters in the same cell reduces the administration efforts to a single console, but raises the effort level to maintain the clusters since there is a high degree of resource sharing between the multiple clusters.
While multiple portal clusters in a single cell has its uses, especially in consolidating content authoring and rendering servers for a single tier, it does increase the administrative complexity significantly. IBM recommends that multiple portal clusters be deployed in multiple cells, to keep administration as simple as possible.


I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Artificial Intelligence Solutions
Data Analytics Services
Data Modernization Services